
Table of Contents
The pull request looked perfect because all checks passed, and the CI pipeline was green from end to end. The team merged before lunch, confident the automation had done its job. By mid-afternoon, staging had locked up under a new API dependency that hadn’t been mocked properly, and rollback took longer than the original feature build.
Eighty-three percent of developers say they are actively involved in DevOps-related activities, yet many still face release performance bottlenecks. That failure rate reflects a mixture of bad code, compounded by incomplete or inconsistent pull request testing.
This guide is for engineering leads, QA specialists, and developers who are done treating automation as background noise. It breaks down how to build a pull request testing system that’s consistent, fast, scalable, and one that teams actually trust.
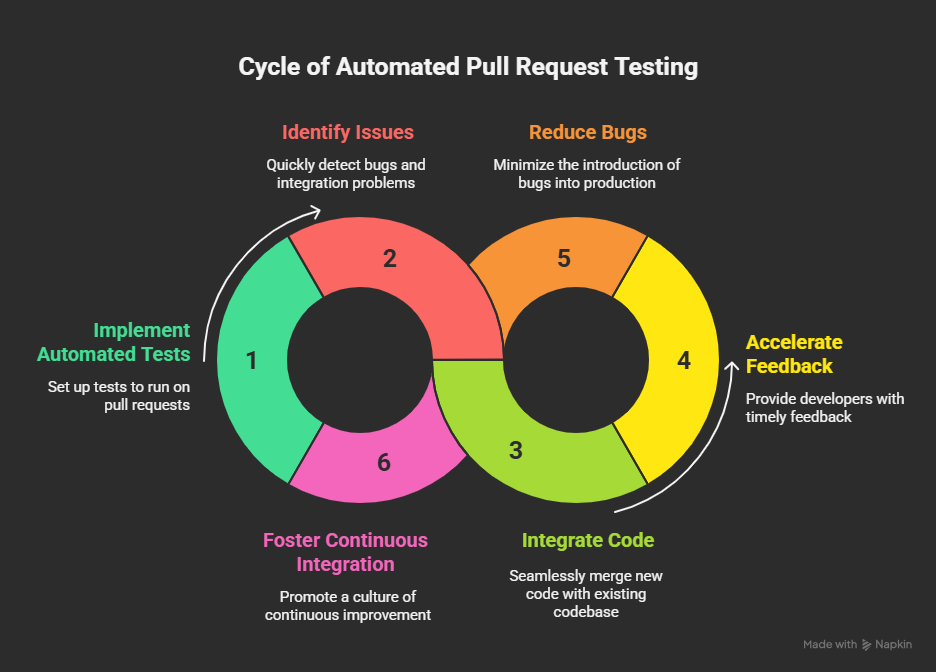
Pull request testing automation uses CI pipelines to automatically run tests on new code before it’s merged. It validates changes under consistent conditions, reducing manual effort and catching regressions early. Automated pull request testing keeps quality consistent across every repository. Each change is validated under the same conditions with the same set of checks.
Automation stabilizes how reviews run. It triggers tests automatically, flags regressions early, and reports failures without waiting for manual action. The feedback loop shortens, and developers gain clear visibility into what passed and what failed. QA and engineering align around a single quality standard instead of separate interpretations.
What actually improves:
- Uniform testing across all branches and repositories
- Lower risk of human oversight
- Faster review and merge cycles
- Shared accountability between engineering and QA
Teams that automate pull request testing release faster and experience fewer production issues. A Global DevSecOps Report found that 67 percent of engineering teams have automated most of their software development lifecycle, which directly correlates with reduced deployment failures and shorter delivery times.

Even strong automation setups fail when process and discipline slip. These are the failure patterns that show up repeatedly across teams.
- Running every test on every pull request.
- Ignoring flaky tests.
- Letting tests go stale.
- Treating failed checks as suggestions.
- Focusing on metrics without meaning.
- Neglecting developer experience.
Automation only adds value when it’s fast, trusted, and current. A reliable pipeline is the one that consistently catches what matters.
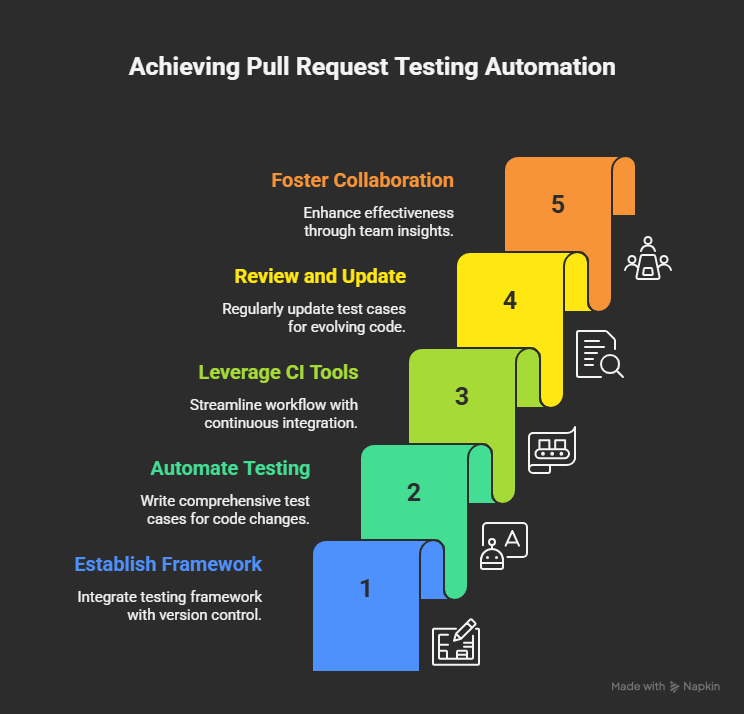
Step 1: Define Your Pull Request Testing Goals
Automating pull request testing starts with clarity. You need to know what the pipeline is meant to protect and what kind of feedback developers need from it. Skipping this step creates the kind of workflow that feels busy but delivers little insight.
Begin with one question: what failure are you trying to prevent? Here are the top 4:
- Frequent regressions. Focus on regression and unit testing that runs on every pull request.
- Integration drift. Add contract and API validation to ensure services stay aligned.
- Slow feedback. Streamline the test matrix and run fast checks early, heavier tests later.
- Unclear coverage. Track coverage metrics per module and fail builds that drop below baseline.
Write down the goal, the signal that confirms it, and the metric that measures it. For example:
- “All critical modules must maintain 85 percent coverage.”
- “End-to-end tests must finish within 10 minutes.”
- “All external API calls must pass contract validation before merge.”
Clear testing goals only hold up when aligned with internal governance. Teams that tie pull request validation to a data security policy ensure every quality gate and enforce how sensitive data should be handled in testing environments.
Step 2: Choose the Right Testing Frameworks
The framework defines how your automated tests behave and how easily they fit into the pull request pipeline. Choosing the wrong one creates friction that never goes away. The right choice depends on your stack, the maturity of your tests, and how you plan to scale them.
Choose frameworks that match your stack and workflow. For JavaScript and TypeScript, Jest is the standard for speed, CI compatibility, and built-in coverage, while Mocha or Vitest suit monorepos that need modular runs. Pytest leads in Python for its simplicity and powerful plugin system that scales from unit to integration testing. In enterprise ecosystems, JUnit and NUnit remain dependable choices with mature tooling, strong IDE support, and predictable test discovery.
When evaluating frameworks, check for:
- Native support for parallel execution
- Built-in coverage and reporting
- Strong community maintenance and plugin support
- Seamless integration with your CI platform
Step 3: Automate Tests in Your CI/CD Pipeline
Tests should be started on each pull request commit. The pipeline should launch a clean environment, install dependencies, and run the specified test suites as soon as code is pushed. To find problems before reviewers even open the diff, run linting, unit, and integration checks in tandem. Make each step brief and foreseeable.
To specify this behavior, use the workflow configuration of your CI/CD platform. The fundamentals remain the same whether using CircleCI, GitLab CI, or GitHub Actions.
Keep automation healthy by:
- Running only what matters for each PR
- Caching dependencies to cut setup time
- Using parallel jobs for heavier test suites
- Storing test artifacts and coverage reports for traceability
This layer serves as the foundation for your release procedure once it is stable. The same procedure is used to validate each new feature, patch, or refactor. Larger teams are able to work fast without sacrificing dependability for speed because of that consistency.
Step 4: Use Isolated Test Environments
Automated testing is only as good as the environment it runs in. Shared staging servers or long-lived branches often cause inconsistent results. An isolated test environment removes that noise and gives every pull request a clean, reproducible space to run.
The idea is simple: each pull request spins up its own environment that mirrors production as closely as possible. Once tests complete, the environment is destroyed. Nothing persists. This eliminates conflicts between concurrent branches and stops one developer’s unfinished work from breaking another’s test run.
Benefits of isolated environments:
- Prevents data collisions between test runs
- Guarantees consistent configuration and dependencies
- Enables parallel testing across multiple branches
- Provides realistic conditions for integration and UI validation
Step 5: Enforce Quality Gates and Test Coverage
A good quality gate does three things: it verifies that tests pass, it checks that coverage meets the minimum threshold, something most code coverage tools track automatically, and it blocks merges when either fails. This creates a non-negotiable baseline for every pull request. No one skips tests because the system does not allow it.
Examples of useful quality gates:
- All tests must pass before merge approval
- Coverage must not drop below the defined baseline
- Linting and formatting checks must pass
- Require status checks to pass before merging; approvals don’t permit merge if checks are red.
Lead times and unsuccessful deployments are decreased by robust gates. Rollback incidents are reduced and deployment confidence is increased for teams that track quality thresholds in addition to DORA metrics. The goal is to maintain the distinction between recklessness and speed, not to impede it.
Step 6: Optimize Test Execution Time
When a pull request takes twenty minutes to clear, developers start batching changes, skipping tests, or merging late. Optimization keeps the feedback loop tight so the automation layer supports velocity instead of slowing it down.
Start by finding what actually takes time. Identify the longest-running test suites and the stages that repeat unnecessary work. Use your CI provider’s timing reports or logs to see where minutes disappear. Most of the delay usually comes from dependency installs, cold environments, or test suites that run more than they need to. Run tests in parallel wherever possible.
Caching also matters. Store dependencies, build artifacts, and coverage data between runs to avoid reinstallation. Every CI system supports this, but many teams forget to fine-tune it. Cache intelligently: too broad and you risk stale data, too narrow and you lose the benefit.
Tactics that make pipelines faster:
- Parallelize tests across runners or containers
- Cache dependencies and build artifacts
- Run quick checks first to fail fast
- Skip unaffected test suites when no related files have changed
- Use lightweight images or runners to cut boot time
AI-driven test selection and review tools are starting to make this process smarter. Platforms like Early Catch can predict which tests need to run based on the files modified in a pull request. That kind of targeted execution keeps validation fast even as the codebase scales.
The objective is predictable speed. Developers should trust that every pull request gets verified in minutes, not quarters of an hour. Fast pipelines sustain healthy release cycles and keep teams focused on writing code instead of waiting for green lights.
Step 7: Leverage AI for Smarter Pull Request Testing
Traditional automation executes tests. AI-enhanced automation writes, updates, and maintains them. It closes the gap between coverage targets and developers' time to meet them. AI agents and code generation tools analyze pull requests, detect changes, and determine which tests are missing or outdated.
Practical use cases for AI in pull request testing:
- Generate missing unit tests for modified functions or modules
- Detect and highlight untested code paths
- Predict which tests are most relevant to the latest change
- Flag unstable or redundant test cases before they waste build time
This is where Early Catch fits in. It integrates directly into CI/CD pipelines and uses an agentic model to maintain test coverage at scale. For every pull request, it generates validated green tests that confirm existing behavior and red tests that expose new issues. The result is a proactive testing layer that evolves with the codebase instead of falling behind it.
AI-assisted testing does not replace developers or QA engineers. It removes the repetition that slows them down, a necessary evolution in an era where autonomous AI systems are reshaping both software and security operations. Teams get consistent coverage, faster feedback, and cleaner merges without having to write every test manually. As projects grow, this is the difference between maintaining confidence in releases and chasing stability after deployment.
Step 8: Monitor and Improve Over Time
Automation is never finished. Once a pull request pipeline is in place, it needs active maintenance to stay reliable. Test suites grow, dependencies change, and what worked three months ago may no longer hold up. Continuous monitoring keeps the system healthy and stops silent failures from eroding trust.
Start by tracking pipeline metrics that reflect developer experience, not vanity data. Look at average test duration, pass rate stability, and flakiness trends. A test that fails randomly is worse than no test at all because it trains developers to ignore warnings. Most CI platforms can export this data automatically for analysis in dashboards or reports.
Use this visibility to identify patterns.
- Which tests fail the most often?
- Where does the pipeline spend most of its time?
- Are failure rates higher on certain branches or modules?
Once you know the weak points, fix them. Quarantine flaky tests until they can be repaired. Remove outdated suites that no longer add value. At higher maturity levels, teams also apply adversarial exposure validation (AEV) tools to simulate real-world attack behaviors and measure how resilient their pipelines are under stress. Reassess coverage thresholds if the codebase expands or risk profile shifts. Healthy pipelines evolve as the product does.
Developing an automated pull request testing system is not meant to take the place of human review. It’s about creating an environment where quality is enforced automatically, and engineers can focus on design, architecture, and performance. Teams that do this correctly view their continuous integration pipelines as dynamic infrastructure that needs to be measured, adjusted, and maintained just like production systems.
The next stage of maturity is now AI-driven testing. It provides developers with trustworthy feedback in minutes rather than hours, detects regressions prior to merge, and maintains coverage up to date. This is made feasible by tools such as Early Catch, which create and manage validated tests right within your CI/CD process.
If you’re ready to see what proactive, self-maintaining pull request testing looks like in practice, book a demo with Early and build the testing system your team will actually trust.