
Table of Contents
Summary
- 1,876 passing unit tests were generated vi CI, fully autonomously, on a real open-source project (ts-morph).
- The agent achieved 76% code coverage across the package
- Mutation score jumped from 53% → 86% → 91% as we focused on methods with generated tests and especially those with 100% method-level coverage.
- For the 150 methods with 100% coverage, mutation scores reached 91%
- EQS (Early Quality Score), our combined metric of Coverage × Mutation Score × Method-Scope Coverage, increased sharply:
- 29% EQS across all 211 methods
- 48% EQS for 185 methods with generated tests
- 91% EQS for 150 methods with 100% coverage
- The benchmark confirms a consistent pattern: When the agent generates direct tests with 100% coverage, the test quality is at 91% mutation score or above.
- This is strong evidence that autonomous test generation at repository scale is viable, reliable, and produces high-quality tests, not just high volume.
We set out to benchmark Early’s Repository Agent on a large-scale open source project, no toy examples, no cherry-picking.
The goal was simple:
Could our agent, running fully autonomously inside CI, generate high-quality, green (i.e. working) unit tests for a real-world repository?
No manual prompts. No human editing. Just autonomous test code generation at repo scale.
Before diving into the results, it's important to understand two key metrics we used: code coverage and mutation scores. These metrics are crucial for evaluating test quality, and their interplay provides a comprehensive view of our tests’ effectiveness. Let's start with code coverage.
One of the most widely accepted methods for measuring test quality is code coverage. Code coverage measures which percentage of the code is covered by tests. If I have zero coverage, clearly my tests either don’t exist or are useless, leaving my code unprotected from future bugs and issues.
However, code coverage is an insufficient measurement on its own. While a low code coverage is indicative of poor testing, high coverage does not necessarily indicate high quality. Even with 100% coverage, the quality of tests might be low. For example, if they don’t cover enough cases of different input datasets. Similar to the low-coverage example, the code still has bugs and issues.
Mutation testing is a software testing technique used to evaluate the quality and effectiveness of the tests themselves. The process involves introducing small changes or "mutations" to a program's source code to create modified versions of the program, known as "mutants." The primary objective of mutation testing is to assess whether the existing test suite can detect and fail these mutants, indicating that the test suite is thorough and robust.
In our benchmark, we used Stryker, a mutation testing framework for JavaScript, TypeScript and more.
How Mutation Testing Works:
1. Generating mutants: The first step in mutation testing is to create multiple versions of the original program, each with a slight modification. These modified versions are known as mutants. Common types of mutations include:
a. Changing a logical operator (e.g., replacing && with ||).
b. Modifying a mathematical operator (e.g., replacing + with -).
c. Altering a constant value.
d. Changing a conditional boundary.
2. Running tests on mutants: Each mutant is tested using the existing test suite. The purpose is to check whether the tests can detect the changes (i.e., cause the tests to fail).
3. Analyzing results: After running the tests, the outcomes are analyzed:
a. Killed mutants: If a test fails due to the mutation, the mutant is considered "killed," indicating that the test suite is effective in detecting that type of fault.
b. Survived mutants: If the tests pass despite the mutation, the mutant is considered "survived," indicating that the test suite did not detect the fault.
c. There are other types of “not killed” mutants, like no coverage, timeouts, and errors.
4. Calculating the mutation score: The mutation score is calculated using the formula:

This score provides a quantitative measure of the effectiveness of the test suite.
Relations between code coverage and mutation scores
Complementary Metrics
- Code coverage and mutation score complement each other. Code coverage ensures that the tests exercise the code, while mutation score ensures that the tests are effective in detecting faults within the exercised code.
Correlation:
- Generally, higher code coverage can lead to a higher mutation score, as more parts of the code are being tested. However, this is not always the case. It's possible to have high code coverage but a low mutation score if the tests are not thorough or effective in catching faults.
Quality assessment:
- A balanced approach using both metrics provides a more comprehensive assessment of test suite quality. High code coverage with a high mutation score indicates that the tests are both extensive and effective. Conversely, high coverage with a low mutation score suggests that the tests need improvement in fault detection, probably with more edge cases tests.
Optimization feedback:
- Code coverage can highlight areas of the code that need more tests, while mutation score can highlight the need for more robust and fault-detecting tests in already covered areas.
Okay, let’s get to the test itself and the results.
To conduct our benchmark, we used a popular OSS project, ts-morph, and the latest Early Repository Agent for test code generation
Test Project ts-morph
ts-morph is an open-source project that provides a powerful and user-friendly API for working with the TypeScript Compiler API. It is designed to simplify the process of interacting with TypeScript code, enabling developers to create, manipulate and analyze TypeScript code programmatically.
- GitHub Stars: 5,800
- GitHub Forks: 224
- Language TypeScript
- Repository https://github.com/dsherret/ts-morph
- Clone date: June 2024
- Tested package: packages/common/src
- Lines of application code (packages/common/src): 4937 LoC
Setup:
- The original tests were removed from the project’s code to mimic a clean slate. This also allows evaluating unit tests in isolation compared to other forms of tests.
- Tests were generated only for packages/common/src
- Using Early Agent for Repository test code generation
- Attempting to generate unit tests for the 211 public methods in this project
Tracked Testing Metrics
We tracked three key metrics:
- Test code coverage — how much of the code was exercised.
- Mutation score –how effective the tests were at catching bugs
- We calculated mutation scores for 3 scenarios:
- All methods
- Methods with generated unit tests (any coverage)
- Methods with generated unit tests & 100% coverage
- Total number of working, green tests - the quality output of test code generation.
Metric
Result
As coverage increased, test quality (mutation score) increased as well.
For most methods, 100% coverage in a results 100% mutation score, meaning the generated tests detected every injected mutant (e.g. bug).
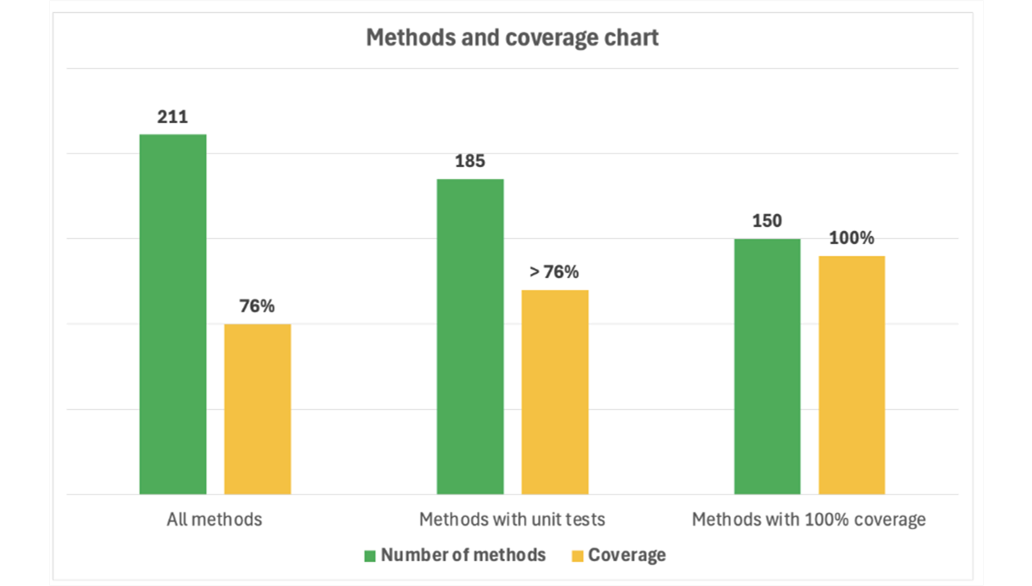
Now, let's break down the mutation score for 3 groups
- The entire project - all files: Mutation score is 53%
- Only for methods where Early generated unit tests at any coverage (at least one unit test): Mutation score is 86%
- Only for methods where Early generated unit tests with 100% coverage: Mutation score is 91%
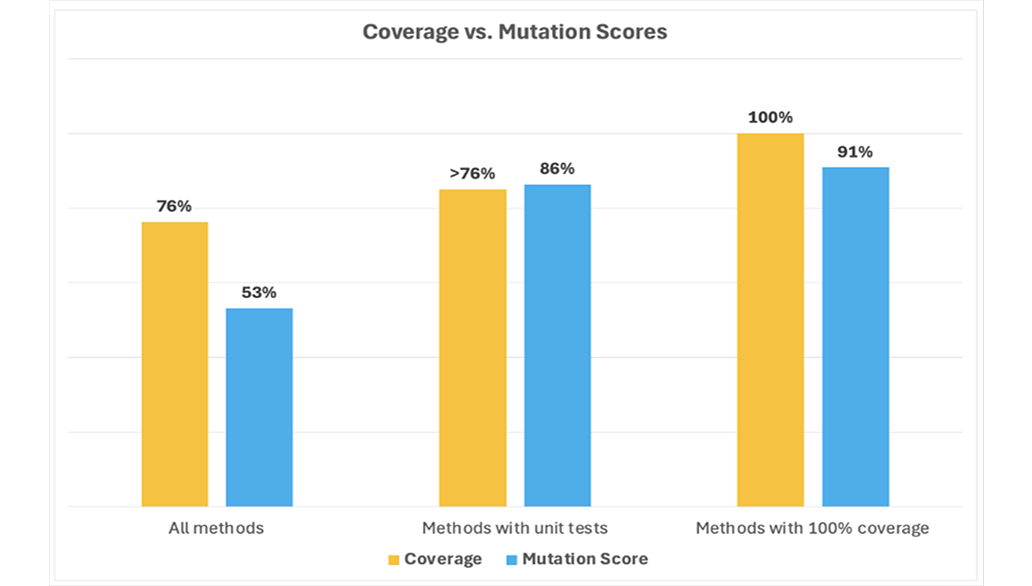
Most AI testing tools stop at coverage. But coverage only tells you how much code is covered, not how well it was tested.
We use mutation testing to go deeper.
It intentionally introduces small code changes (“mutants”), flipping conditions, tweaking operators, and checks whether the tests detect the change.
If a test fails when a mutant is introduced, that’s a good thing, it means the test is actually protecting against real bugs.
So while 76% coverage is strong, what’s more important is that our mutation score climbed from 53% overall to 91% for methods that have 100% coverage.
That’s not just test quantity - that’s test quality.
The graph below shows more accurate mutation score calculation only for methods with certain coverage thresholds.
Out of the 211 methods on this project:
- 185 methods had unit tests (i.e. any coverage) and 86% mutation score
- 150 methods had unit tests with 100% coverage and 91% mutation score

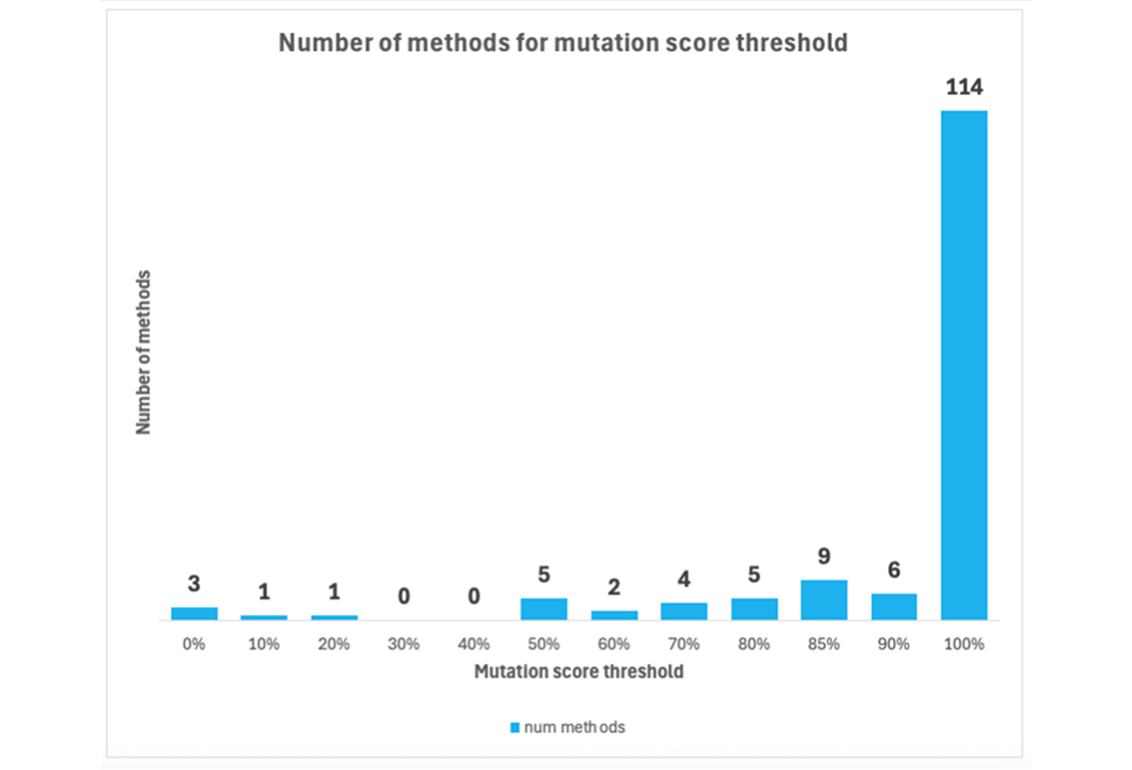
Further analysis of the 150 methods with 100% coverage reveal that most of them have mutation score 80% or above, and three quarters (114 methods) have a perfect mutation score of 100%
(If you’re new to EQS, see our full explainer )
EQS is a metric we use to measure the true quality of a test suite.
Unlike coverage alone, EQS combines three signals:
EQS = Coverage × Mutation Score × Method-Scope Score
Where:
Method-scope score = the ratio of public methods that have direct tests (unit, component, or endpoint) with 100% coverage for that method.
EQS Results for ts-morph
EQS Results for ts-morph
As we narrow the scope to methods where direct, high-quality tests were generated, EQS rises sharply.
This mirrors what we consistently see across benchmarks:
high method-level coverage → high mutation score → high EQS.
What We Aim For
At Early, our target is 100% EQS:
Every testable method should have direct tests, with 100% method coverage, and 100% mutation score (meaning no injected bug goes undetected).
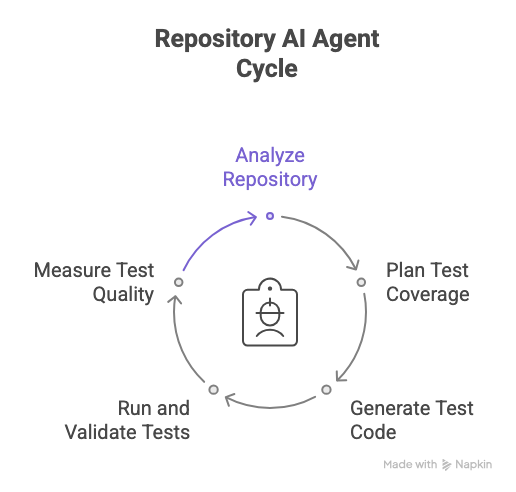
The Repository Agent acts like an autonomous test engineer living inside your CI. It executes the following steps:
- Analyzing your repository to identify testable methods and dependencies.
- Planning test coverage intelligently, prioritizing critical or uncovered areas.
- Generating test code using contextual understanding of your repo.
- Running and validating those tests, automatically fixing any failing ones.
- Measuring coverage and mutation scores to verify the generated test’s quality. And because it’s embedded directly into CI, the entire process runs automatically and periodically for every repository and, pull request.
And because it’s embedded directly into CI, the entire process runs automatically and periodically for every repository, pull request, or scheduled build and protects your code continuously.
What We Learned
Running this benchmark at scale gave us several valuable insights:
- Coverage alone isn’t enough. The correlation between coverage and mutation score proved that test quality must be measured, not assumed.
- Autonomous generation works. The agent produced thousands of green tests without human intervention, showing that continuous test code generation in CI is not just possible, but reliable.
Why This Matters
For engineering leaders, it means consistent, measurable quality that scales with your organization and standardizes how tests are created.
For developers, this means more time building, less time maintaining brittle tests.
AI test code generation is no longer a demo feature, it’s an autonomous system that can continuously improve the quality and reliability of your codebase.
This benchmark proves it.
Early’s Repository Agent generated:
- 1,876 working tests
- 76% coverage
- 91% mutation score for methods with 100% coverage
- High coverage with Early generated tests means high quality
- All autonomously, directly from CI.
That’s what real AI test code generation looks like.
We’re expanding this benchmark to more frameworks (React, JS, Python), deeper mutation analysis, and long-term stability testing.
If you’d like to see what the Repository Agent can do on your own repo check our repo-cli-introduction documentation and book a demo here.
And if you want to check out the tests and the results yourself, we’ve made them public. You can explore everything in this public Early clone of ts-morph with all the generated tests under package/common/src on github
FAQs
How is AI test code generation different from traditional “AI for testing” tools?
Most AI testing tools analyze tests or help you run tests more efficiently. Early’s Repository Agent focuses on generating real, maintainable unit tests that live in your repo. It acts like a senior engineer who writes and validates tests continuously, so your team spends less time authoring or fixing brittle testing suites.
Can the agent generate high-quality tests if my codebase is complex?
The Repository Agent analyzes code structure, dependencies, and method behavior before generating tests. Quality isn’t assumed, it’s verified using both coverage and mutation scoring.
How does mutation testing improve test quality?
Code coverage only tells you whether code ran during tests, not whether the tests can detect logic errors. Mutation testing introduces small “mutant” changes to the code. If the test suite fails, it means the test is protective; if the test still passes, the test is weak. Using coverage + mutation score together is what ensures generated tests are actually capable of catching regressions.
How does the agent run inside CI?
The Repository Agent integrates directly into your CI pipeline. On each run (e.g., a pull request, merge, or scheduled nightly build), it analyzes the repo, generates or updates tests, executes them, and verifies their validity. If tests need fixing, it auto-patches them.
Can the Repository Agent scale to very large codebases or multiple repos?
The agent can continuously generate and maintain tests across large repositories, multi-package monorepos, and services. It prioritizes uncovered or high-impact areas first, rather than trying to brute-force everything at once.